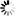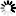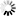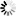
核心提示:首先,我们来看一个简单的网页https://www.pythonscraping.com/pages/page3.html,打开后:右键检查(谷歌浏览器)查看元素:用导航树的形式简单表示出来:可知:t...
首先,我们来看一个简单的网页https://www.pythonscraping.com/pages/page3.html,打开后:

右键“检查”(谷歌浏览器)查看元素:

用导航树的形式简单表示出来:

可知:
tr是table的子标签
tr、th、td、img、span标签都是table的后代标签
一般情况下,bbs0bj.body.h1选择的是body标签后代里的第一个h1标签,不会去找body外面的标签
类似的,bs0bj.p.findall("img")会找到第一个p标签,然后获取这个p后代里面所有的img标签
1. 处理子标签和后代标签
如果你想获得子标签,可以用.children标签:
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen("https://www.pythonscraping.com/pages/page3.html")
bsObj = BeautifulSoup(html)
for child in bsObj.find("table",{"id":"giftList"}).children:
print(child)
部分结果如下:

如果你用descendants()函数,就会获得每个后代标签
2. 处理兄弟标签
BeautifulSoup中的next_siblings()很擅长处理带标题行的表格:
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen("https://www.pythonscraping.com/pages/page3.html")
bsObj = BeautifulSoup(html, "html.parser")
for sibling in bsObj.find("table",{"id":"giftList"}).tr.next_siblings:
print(sibling)
得到部分结果如下: 
如果你很擅长找到一组兄弟标签中的最后一个标签,那么previous_siblings()函数 另外,next_sibling(),previous_siblings()返回单个标签
3. 处理父亲标签
抓取网页的时候,父标签用到的很少,用parent和parents抓取,举个例子:
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen("https://www.pythonscraping.com/pages/page3.html")
bsObj = BeautifulSoup(html, "html.parser")
print(bsObj.find("img",{"src":"../img/gifts/img1.jpg"}).parent.previous_sibling.get_text())
输出:
$15.00
可以这样理解:

(1)选择图片标签 (2)选择图片标签的父标签 (3)选择标签前面的一个兄弟标签 (4)选择标签中的文字