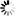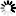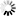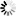
L1、L2正则化
过拟合:对于训练集拟合效果非常好,但是对于训练集以外的数据集拟合效果不好。通常发生在变量(特征)较多的情况,也就是说曲线尽可能的满足训练数据集,导致无法泛化(泛化是指模型能够应用到新样本的能力)到新数据集中。解决办法:减少样本特征、正则化(通常添加L2正则化)
欠拟合:模型没有没有很好的捕捉到数据特征,不能够很好的拟合数据。与过拟合是相反的。其解决办法:添加其他特征项、添加多项式特征、减少正则化参数。
第一张图表示欠拟合,可以看出很多类别被分类错误。
第二张图表示拟合,就是拟合效果比较好。
第三张图表示过拟合,在此数据集上拟合效果非常好,可以想象一下,其在实际应用中效果将会非常差。

(正则化代价函数)=(经验代价函数)+(正则化参数)X(正则化项)
经验代价函数是实际与预测的误差,我们不仅需要训练误差小,还想要测试误差小,因此引入第二项正则化约束函数,使得模型尽量简单。
Q1:什么叫做正则化?
L0正则化:表示矩阵中非0元素的个数。简单粗暴的来说就是要是参数w稀疏,但是其往往难以求最优解,因此通常使用L1正则化进行稀疏。
L1正则化:是指各个元素的绝对值之和。Lasso Regularization,其是L0范式的最优凸近似。
L2正则化:是指各个元素的平方和再求平方根。防止过拟合。
Q2:L0、L1为什么能实现稀疏,为什么需要稀疏?
我们在进行训练模型的时候,特征中部分特征对实际的预测输出并没有贡献,因此在预测新样本时,将会对预测输出造成影响。稀疏规则化算子的约束就是为了完成特征自动选择,去掉对预测无用的特征,也就是说将这些无用的特征的权值设置为0。令一个方面添加稀疏正则化能够更好的解释模型。举个例子来说,假如预测病人是否患有癌症,其影响的因素有,饮食口味、家族病史、睡眠质量、运动情况、性别、年龄、文化程度等等,最后通过学习,我们发现只有饮食口味、家族病史和睡眠质量影响是否患癌,也就是说其他的运动情况、性别、年龄、文化程度等特征权重为0,这样就能够简化我们的预测模型。